Local LLM 101: Running LLMs locally
For the non-technical people, or first timers…
This article is meant to give a very high-level overview of running Large Language Models (LLM) locally on your own computer. This short article will not dig into the nitty gritty of running LLMs, and it will generalize a lot of ideas for simplicity. The intended audience is people without any coding background, or programmers who never ran an LLM locally.
TL;DR Get LM Studio or Jan on your computer. Download an LLM model of your choice, or choose one from the suggestions below, that’s it!
 Photo by Neeqolah Creative Works on Unsplash
Photo by Neeqolah Creative Works on Unsplash
Why Run LLMs locally?
There are many advantages of running LLMs locally on your machine rather than using cloud-based solutions like ChatGPT or Gemini, here are a few of them:
- Data Privacy and Security — Depending on the software you use to run the LLM locally, all your data and interactions with the model stay on your computer. This is ideal for handling private and sensitive information, as using a cloud-based solution means your data leaves your computer and is sent to a third-party server, where it can even be used for training their LLMs or profile you.
- Offline Usage — Running an LLM locally means you don’t need an internet connection to interact with the model.
- Customization and Control — You have the flexibility to customize your local LLM parameters as you see fit.
- No Censorship — While censorship of LLMs by companies is understandable in many situations, it has been shown that companies and even governments censor LLM outputs to mute criticism and inject biases. Unless the LLM you are running locally is very carefully trained on censored data, you can bypass any sort of censorship quite easily.
- Reliability and Independence — Running LLMs locally means you are not relying on the uptime of third-party services like ChatGPT or Gemini. Some companies only allow you to send a certain number of queries to the LLM, but running locally frees you from any sort of rate restrictions.
Downloading the software
There are many different ways to run Large Language Models locally. However, popular options like llama.cpp and Ollama are not easy to use for people without a coding background, as they require extensive use of the terminal. GPT4All, LM Studio, and Jan are three popular options for running LLMs locally that are also quite user-friendly for non-technical people.
Among these, in my opinion, GPT4All has a bit of room for improvement in its UI design. Therefore, I would recommend either LM Studio or Jan, both of which have a nice and intuitive user interface. Personally, I prefer LM Studio because, as a Mac user, it allows me to directly run Apple Silicon optimized MLX models in it (see below), and their UI is slightly better than Jan’s.
 The LM Studio homepage
The LM Studio homepage
It is important to note that LM Studio’s desktop app is not open source. Their internal LLM runtime and APIs, however, are fully open sourced. In contrast, both GPT4All and Jan are fully open source.
LM Studio’s Privacy Policy states the following:
- None of your messages, chat histories, and documents are ever transmitted from your system — everything is saved locally on your device by default.
- The only occasions where we receive anything about your usage of LM Studio:
- When you search for, or download an AI model (so that we can get you the model over the internet).
- When the app checks for software updates (so we can get you the updates over the internet).
Please make sure to review their privacy policy before proceeding.
To download LM Studio or Jan 👋, go to https://lmstudio.ai or https://jan.ai and follow the instructions from the front page.
🧐 Psst. What is LLM Inference? It’s just a fancy name for text generation from the LLM…
Got it… but, which LLM should I run? 🤔
 “Ecstasis et Ruina” — ChatGPT fecit, circa 2025
“Ecstasis et Ruina” — ChatGPT fecit, circa 2025
Well, glad you asked! To choose the right LLM to run locally, there are a few things you need to consider, such as hardware considerations, model format, type of model, and model prompt configuration.
Hardware Consideration 🛠️
To run Large Language Models locally, your hardware is the most significant factor to consider. While having a powerful CPU is recommended, it’s not as important as your GPU memory (VRAM) or system memory (RAM). Generally, if the size of the LLM model file you intend to run is smaller than your VRAM or RAM (or their combined total), you can run it on your computer. However, if you fully load your VRAM or RAM with the LLM, the inference speed may be significantly slow. Therefore, it’s essential to allocate some wiggle room. VRAM is typically better suited for running LLMs due to its faster speed through parallel processing.
In Windows and Linux systems, VRAM can be obtained through an NVIDIA graphics card such as the 3090, 4080, etc. On Mac systems equipped with Apple M-Series chips, a portion of your RAM is allocated to VRAM. For instance, if you have a 16 GB M3 Mac, part of this memory is dedicated to VRAM. This is called Unified Memory.
From my personal experience, you can make an educated guess about whether a quantized LLM (see below) will run on your computer by looking at the number of parameters the model has. For example, if the model has 8 billion parameters, a quantized version will likely fit in an 8 GB memory system. However, running an 8 billion-parameter model on an 8 GB memory system will likely result in very slow performance. I recommend filling at-most half of your available memory with the LLM. For an 8 GB memory system, I would recommend running a model with 1–4 billion parameters. For a 16 GB memory system, you can try between 1 and 8 billion parameters. I do not recommend running models with fewer than 1 billion parameters, as these are usually erratic and less useful for regular use.
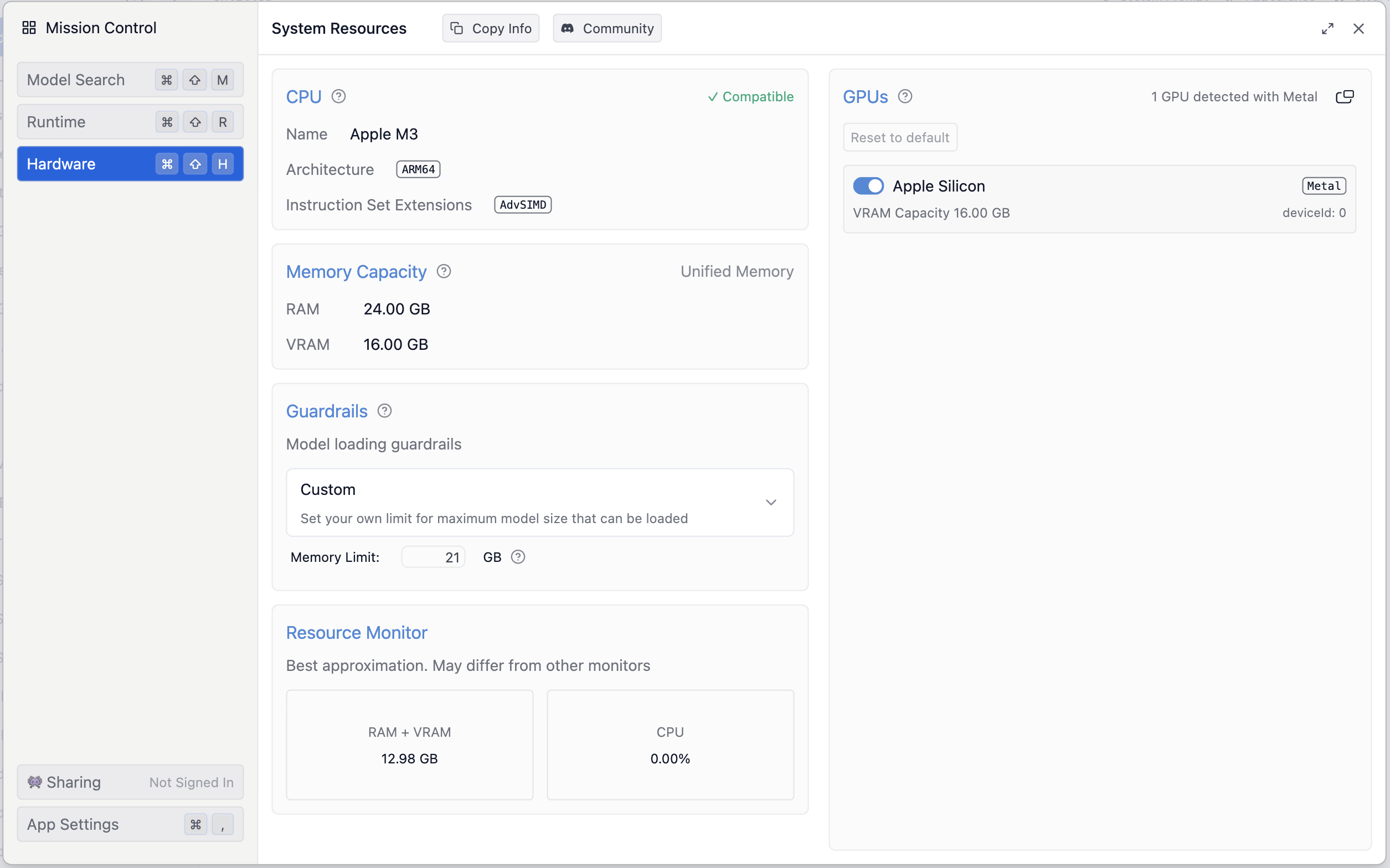 Screenshot showing system RAM and VRAM information on LM Studio
Screenshot showing system RAM and VRAM information on LM Studio
On LM Studio, you can easily find your RAM and VRAM by navigating to the “Discover” tab (🔍 icon) on the left and then clicking on the “Hardware” tab. Your RAM and VRAM will be listed under memory capacity. As shown in the image above, this particular Apple M3 system has 24 GB of RAM and 16 GB of which is dedicated to VRAM. Therefore, while it can fit at least 24 billion parameter models, running models with 1–12 billion parameters or those whose model file sizes are around 12 GB will perform quite well on this machine.
In Jan, you can go to the “Settings” (⚙️ icon) at the bottom, and then select Hardware from the menu.
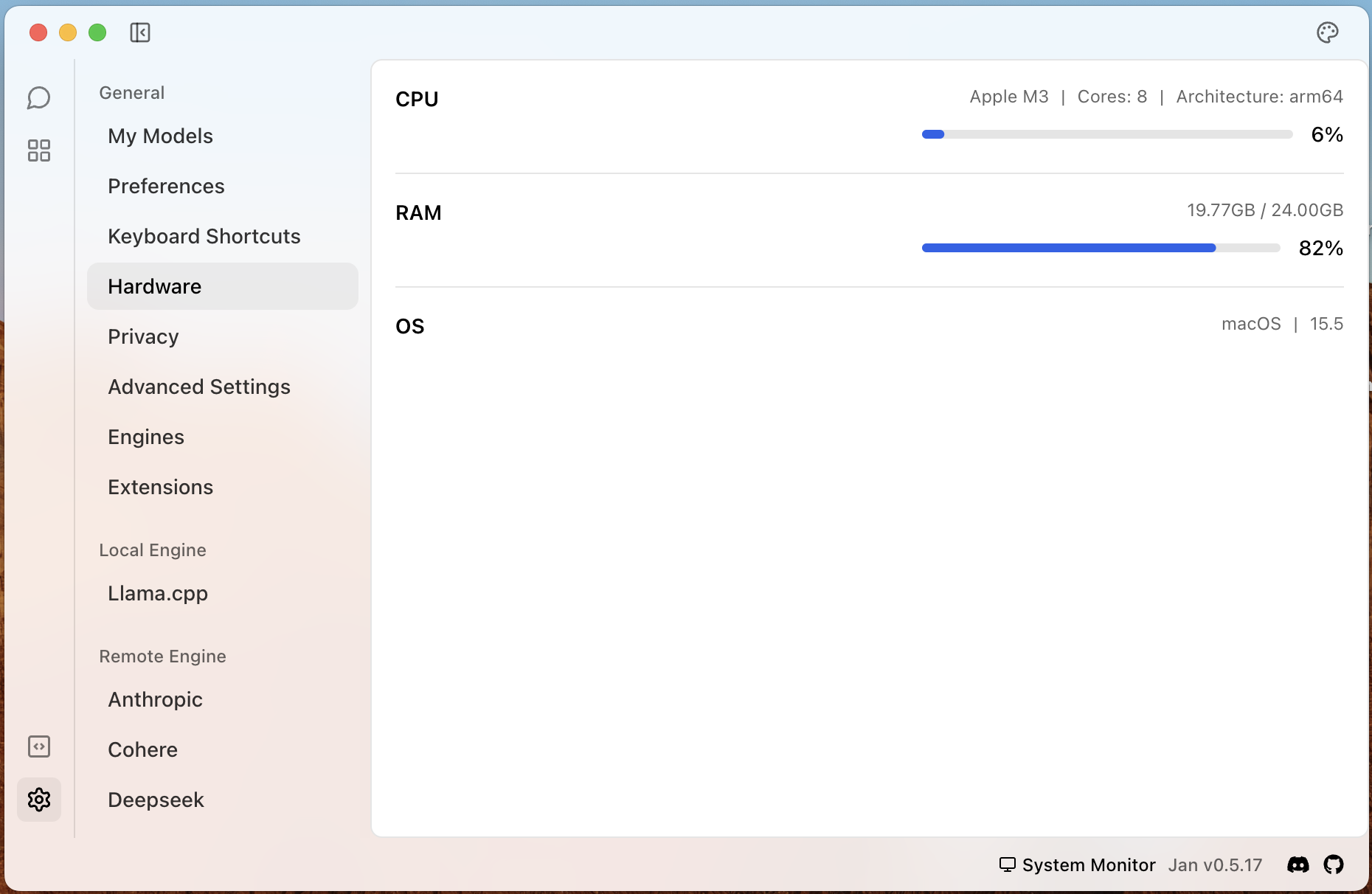 Screenshot showing system RAM and VRAM information on Jan 👋
Screenshot showing system RAM and VRAM information on Jan 👋
Types of models
🔠 Basic text — These are standard LLMs that only take text as input and generate text as output.
👁️ Vision models/Vision Enabled — These models have the added capability of processing images in addition to text. They take both image and text as input and return a text-based response.
🧠 Reasoning models — These models include a deliberate “thinking” step before generating a final answer. DeepSeek-R1 is a good example. I don’t recommend them for local use, as these can spend a long time “thinking” before giving you a final response. Nonetheless, these models are fun to explore.
🥗 Multimodal models — “Multimodal” means multi input and/or output types for LLMs. Vision enabled LLMs can also be called multimodal models. These are models that can take in and/or respond in text, image, sound, or other multimedia types.
🏙️ LLM architecture types — In addition to various types of models, there are also two main types of LLM architecture:
Dense — Simple monolithic architecture, where every parameter in the model is used for every input and output step. Easier to run locally for small to mid-size models, as all parameters can fit in RAM and be actively processed at each step.
MoE (Mixture of Experts) — These models consist of many specialized subnetworks that together form the entire artificial neural network of the LLM. These subnetworks are called ‘experts,’ and during generation, only a subset of them is activated. Meta’s Llama 4 models use the MoE architecture. These models are not usually easy to run locally, as the presence of multiple expert subnetworks increases the overall size of the neural network or parameter count of the model. As a result, the model typically exceeds the RAM/VRAM capacity of consumer-grade hardwares.
What is quantization?
 ChatGPT generated image describing quantization on a very high-level
ChatGPT generated image describing quantization on a very high-level
Quantization is a process by which a full-sized model is converted to a smaller size, with some impact on accuracy. Inside a full-sized LLM, each of the artificial neural network parameters/weights are usually represented as either 32-bit or 16-bit floating-point numbers (32 or 16 digit binary numbers). Quantization algorithms can convert each of these 32-bit and 16-bit floating-point numbers into smaller binary digit sizes, such as 8-bit, 4-bit, etc. Converting these larger numbers into smaller ones means you lose model accuracy; however, different quantization algorithms have been invented where this loss is quite minimal or insignificant. By converting these larger binary numbers into smaller ones, quantization reduces the overall size of the models, allowing you to fit these models on consumer hardware.
What is GGUF? What is MLX?
🚀 GGUF — This is the most popular quantized model file format. It was developed by the extremely popular llama.cpp community. LLM models in this file format can run on Linux, Mac, or Windows machines.
🍎 MLX — This is a machine learning framework developed by Apple. It is specifically designed to accelerate machine learning tasks on Apple M-series chips. On my Mac, I usually get at least a 20–30% boost in inference speed when using quantized models that are converted to the MLX format.
As of writing this article, Jan only supports GGUF models, while LM Studio supports both GGUF and MLX format models.
How to download LLMs locally
To download an LLM on LM Studio after the initial setup, you can go to the “Discover” tab (🔍 icon) and search for your desired model or paste the Huggingface model URL and then download. You can also choose one of the staff pick models that is presented to you when you first open the menu. For Jan, you can choose the “Hub”(⊞ icon) tab on the left hand side, and then search or paste a Huggingface model URL to download.
Video showing how to download LLMs locally on LM Studio and Jan
Here are some good sources on Huggingface to find GGUF/MLX models. Scroll down, search and find your desired model, and paste the link on LM Studio or Jan. These days, companies such as Google, Meta, and others release GGUF and MLX versions of their models as well on Huggingface.
🚀 GGUF
🍎 MLX
While running models locally, I almost always stick with 4-bit or 6-bit quantized LLMs (but, mostly 4-bit ones). Anything higher than this, such as 8-bit or fp16, is basically filling up your memory without substantial gains in quality. Anything lower than this, such as 2-bit or 1-bit, is virtually unusable.
MLX models usually directly state 4-bit and 6-bit right on the model name. For example: mlx-community/gemma-3–12b-it-4bit-DWQ.
For GGUF models, paste the link to the Huggingface model repository on LM Studio/Jan, and from the list of options, choose an option that says Q4, Q5, or Q6 in the name, these correspond to 4-bit, 5-bit and 6-bit quantizations. For example, Q4_K_S, Q6_K_L, etc.
For example, for unsloth/phi-4-GGUF, LM studio will show you an option like such:
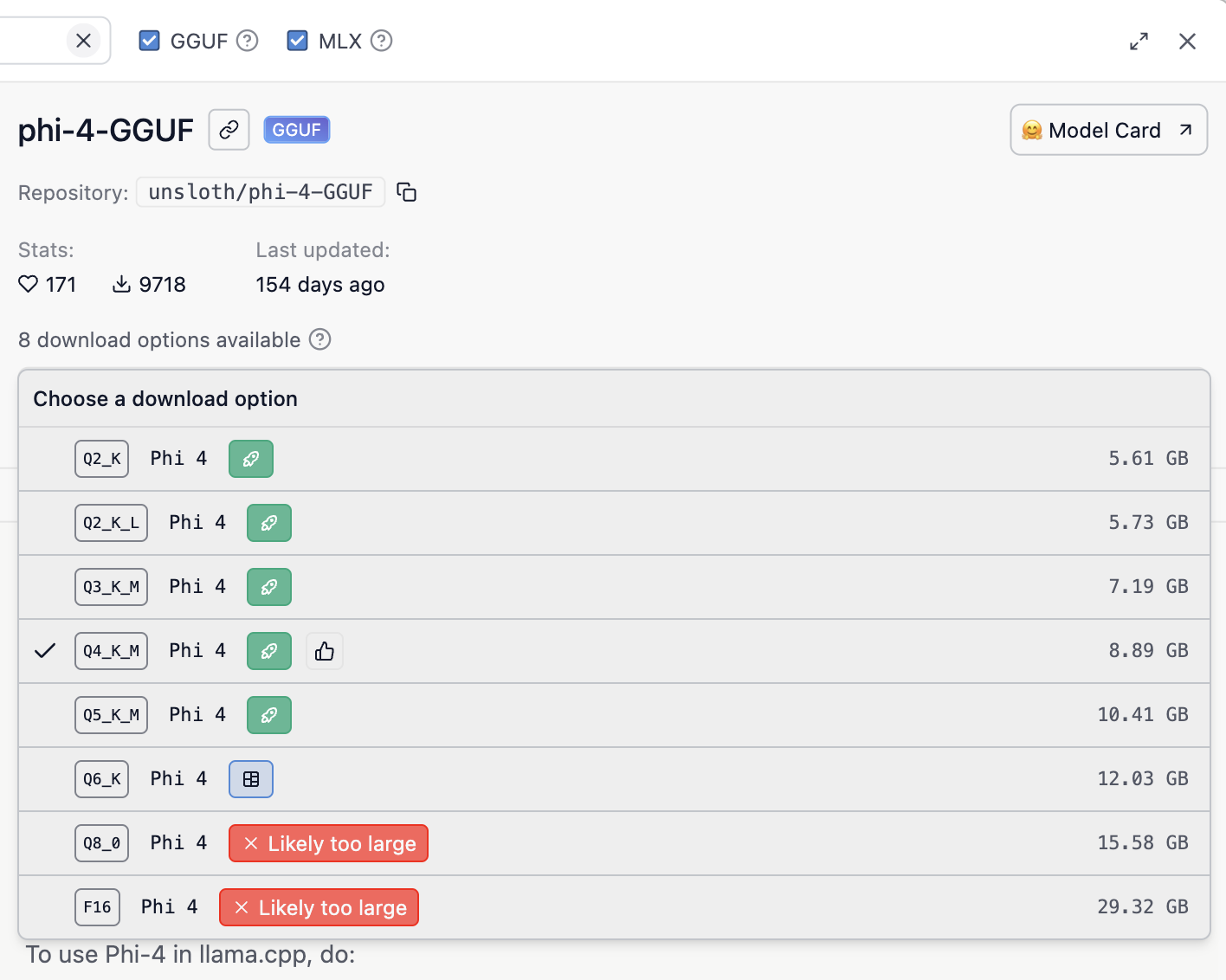 Screenshot from LM Studio showing quantized model download options
Screenshot from LM Studio showing quantized model download options
Some model suggestions
Around 8GB RAM/VRAM:
Around 16GB RAM/VRAM:
- Google Gemma 3 12B — GGUF, MLX (vision enabled)
- IBM Granite-3.3 8B — GGUF
- Meta Llama 3.1 8B — GGUF, MLX
- Mistral 7B — GGUF, MLX
Just for fun:
- Smollm2–1.7b-instruct — GGUF — Small model, only 1GB RAM/VRAM requirement.
- Granite-3.3–2b-instruct — GGUF, MLX — Another small model, that also produces proper responses.
- qwen/qwen3–4b (Reasoning) — GGUF, MLX — Small reasoning model that “thinks” before it answers. Some prompts may take minutes to complete, but it’s still fun to experiment with.
- Mistral Small 24B — GGUF, MLX — Very capable, better than OpenAI’s GPT 4o-mini. Requires around 12–14GB RAM/VRAM. Inference speed is not very fast on my 24GB M3 Mac Air, but it is still quite usable.
How do I run the model, exactly? 🤨
To run the model on LM Studio, go to the Chat tab, select the model you downloaded from the dropdown menu at the top, and then click on “Load Model”. Then, you can start chatting with your local LLM.
In Jan, select the settings menu from the chat input, and then select your desired model from the dropdown. Then, you can start chatting.
Video showing how to run LLMs locally on LM Studio and Jan
Below are some optional configuration settings for your local LLM. Instructions on how to modify these settings are shown in the video above.
💻 System Prompt/Instruction — This is like giving your assistant a job description or personality. For example, you can tell it to “only respond using poems” or “be a pirate”, etc.
🌡️ Temperature — Think of this as how creative or random the responses will be. A lower temperature (like 0 or 0.2) makes the model more focused and predictable. A higher temperature (like 0.8 or 1.0) makes it more imaginative and free-flowing.
👀 Context Length — This is how much conversation the LLM can remember at once. It’s like a short-term memory. A longer context length means it can refer back to more of the conversation or text, which helps it stay consistent and follow complex discussions. The larger the context length, the more RAM/VRAM your model will need to run. For general use, you can use the default setting or set it to something between 4,500 and 5,000.
Some model naming conventions
Let’s unpack some basic quantized LLM naming conventions. First, let’s take this model name: “mistral-small-24b-it-Q4_K_S-GGUF”.
- “mistral-small” — This is the model name.
- “-24b” — This indicates the number of parameters in the model. Here, 24b stands for 24 billion.
- “-it” — This stands for Instruction Tuned, meaning the model has been fine-tuned for chat or instruction-following tasks. When running LLMs locally for chat purposes, you should always look for models that include “-it” or “Instruct” in the name.
- “-Q4_K_S-GGUF” — This denotes the quantization method used. Q4 refers to 4-bit quantization. “K_S” provides additional details about the specific quantization variant (you can usually ignore this information as a basic user). And, GGUF is the model format.
Now, let’s look at another example: “Llama-3.2–3B-Instruct-8bit”.
- “Llama-3.2” — The model name.
- “-3B” — Indicates 3 billion parameters.
- “-Instruct” — Instruction-tuned, equivalent to “-it”.
- “-8bit” — Indicates 8-bit quantization.
In addition to these elements, you might see other tags in the model name such as “bnb”, “DWQ”, etc. As a normal user, you can usually ignore these information.
How do I keep track of new LLM releases and advancements?
You really don’t! It’s not humanly possible to keep track of everything in this AI hype cycle. However, you can try checking the trending models section on Huggingface, or follow the LocalLlama subreddit to stay somewhat up-to-date with developments in the local LLM space. That said, these platforms often fall victim to manipulated trends/social engineering due to bots from companies, research centers, and governments upvoting posts and artificially boosting engagement to promote their AI models.
 “Allegoria de Vanitate et Sapientia Artificialis” — ChatGPT fecit, circa 2025
“Allegoria de Vanitate et Sapientia Artificialis” — ChatGPT fecit, circa 2025
That’s it… bye! 👋